


Big Data
Las tecnologías de mayor impacto para la sociedad, que se han desarrollado exponencialmente durante los últimos años, tienen un punto en común:
Todas ellas precisan o manejan ingentes cantidades de datos.
Si quieres obtener un modelo de inteligencia artificial relativamente robusto vas a necesitar un gran dataset. Si quieres analizar y extraer información de las transacciones registradas en el libro mayor inmutable de una blockchain (que además crece conforme pasa el tiempo) vas a necesitar tecnología capaz de procesar millones de datos.
La tech Big Data es y será la solución a estos retos. Si la tendencia es la IA y la Blockchain, la tecnología Big Data será, sin duda, el motor que mantenga el crecimiento de las mismas.Juan Miguel Martos
| Tech | Blog | Fecha |
|---|---|---|
| Hadoop | Un paseo por Hadoop | 12/01/2021 |
| HDFS | Hadoop Distributed File System | 15/01/2021 |
| SQL | Guía Práctica de SQL | 22/01/2021 |
| HIVE | Hive desde 0 | 03/04/2022 |
| Sqoop | Sqoop = DDBBs + Hadoop | 28/01/2021 |
| Zookeeper | Cluster de Alta Disponibilidad | 02/02/2021 |
| Spark | Spark, Scala y HDFS | 06/02/2023 |
| HBASE | HBase: NoSQL Distribuido | 10/02/2021 |
| PySpark | Spark DataFrames & SQL | 14/04/2023 |
| ... | ... | ... |
Un paseo por Hadoop.
En el mundo actual, el manejo de grandes cantidades de datos se ha vuelto crucial para la toma de decisiones empresariales y científicas. Para manejar estos volúmenes de datos, se utilizan tecnologías especializadas como Apache Hadoop. Este sistema open source permite almacenar y procesar grandes cantidades de datos distribuyéndolos en diferentes nodos de un cluster. En este artículo, discutiremos cómo utilizar Apache Hadoop y sus herramientas asociadas.
Trabajando con HDFS (Hadoop Distributed File System)
HDFS es el sistema de archivos distribuido de Hadoop. A continuación se presentan algunos comandos útiles para trabajar con HDFS:Para ver el contenido de un directorio en HDFS:hadoop fs -ls /ruta/directorioPara crear un directorio en HDFS:
hadoop fs -mkdir /nombre\_dirPara eliminar un archivo o un directorio de HDFS:hadoop fs -rm /ruta/file
hadoop fs -rm /ruta/dirPara subir un archivo al sistema HDFS:hadoop fs -put /ruta/archivo\_local /ruta/directorio\_hdfsPara bajar un archivo desde HDFS a una ruta local:hadoop fs -get /ruta/archivo\_hdfs /ruta/directorio\_localPara copiar archivos:hadoop fs -cp /ruta/archivo\_origen /ruta/archivo\_destinoPara mover archivos:hadoop fs -mv /ruta/archivo\_origen /ruta/archivo\_destino
Trabajando con MapReduce.
MapReduce es el framework de procesamiento distribuido de Hadoop. A continuación se presentan algunos comandos útiles para trabajar con MapReduce:Para ejecutar un job de MapReduce en el cluster:hadoop jar nombre\_del\_jar.jar nombre\_clase\_principal arg1 arg2 ...Para listar los jobs y su información:
hadoop job -listPara ver el estado de un job en ejecución:hadoop job -status job\_idPara cancelar un job en ejecución:hadoop job -kill job\_idPara ver los logs de un job:hadoop job -logs job_id
Trabajando con un cluster de Hadoop.
Para trabajar con un cluster de Hadoop es necesario tener acceso a los nodos del mismo, ya sea mediante SSH o mediante una interfaz web como Cloudera Manager o Ambari. Una vez tengamos acceso a los nodos, podremos ejecutar los comandos necesarios para trabajar con HDFS y MapReduce.Para ver el estado de los nodos y el espacio utilizado y disponible en el cluster:hadoop dfsadmin -reportPara añadir un nuevo nodo al cluster:hadoop dfsadmin -addDatanode IP\_NODOPara eliminar un nodo del cluster:hadoop dfsadmin -decommission IP\_NODO
Herramientas asociadas a Hadoop.
Además de MapReduce, existen varias herramientas y frameworks que se utilizan para analizar los datos almacenados en el cluster. Algunas de las más populares incluyen:Apache Hive: un sistema de almacenamiento de datos estructurados sobre HDFS, que proporciona una interfaz SQL para acceder y analizar los datos.Apache Pig: un lenguaje de programación para procesar grandes conjuntos de datos en Hadoop.Apache Spark: un motor de procesamiento de Big Data que permite realizar tareas de análisis y procesamiento en cluster de manera rápida y eficiente.Apache Mahout: un framework de aprendizaje automático para el procesamiento distribuido en Hadoop.En conclusión, Apache Hadoop es una herramienta esencial para manejar y analizar grandes cantidades de datos en un ambiente distribuido. Utilizando comandos básicos de HDFS y MapReduce, así como herramientas asociadas como Hive, Pig, Spark y Mahout, se pueden realizar tareas de almacenamiento, procesamiento y análisis de datos de manera eficiente desde la terminal. Es importante recordar que Hadoop es solo una de las opciones de big data que existen y es importante evaluar cual es la mejor opción para las necesidades específicas de cada proyecto.
HDFS
Hadoop Distributed File System (HDFS) es un sistema de archivos distribuido diseñado para almacenar grandes cantidades de datos en una arquitectura de cluster. Fue desarrollado por Apache Software Foundation como parte de la plataforma Hadoop. HDFS es escalable, tolerante a fallos y de bajo costo, lo que lo convierte en una excelente opción para el almacenamiento de datos masivos.HDFS se divide en dos componentes principales: el NameNode y el DataNode. El NameNode es el encargado de mantener el índice de los archivos en el sistema y de dirigir las operaciones de lectura y escritura. El DataNode es el encargado de almacenar los datos. En un cluster HDFS, hay un solo NameNode y varios DataNodes.Los datos en HDFS se dividen en bloques y se distribuyen entre los diferentes DataNodes. Cada bloque se almacena en tres replicas, para garantizar la tolerancia a fallos. Esto significa que si un DataNode falla, los datos todavía estarán disponibles en dos copias.Para interactuar con HDFS, se pueden utilizar comandos de terminal Linux. A continuación, se presentan algunos ejemplos de código para trabajar con HDFS:Crear un nuevo directorio en HDFS:hdfs dfs -mkdir /usuariosEste comando se utiliza para crear un directorio en HDFS, en este caso en la ruta /usuariosSubir un archivo a HDFS:hdfs dfs -put informe.txt /documentos/informe\_hdfs.txtEste comando se utiliza para subir un archivo desde el sistema local a HDFS, especificando la ruta de origen y destinoDescargar un archivo de HDFS:hdfs dfs -get /imagenes/foto1.jpg foto1\_local.jpgEste comando se utiliza para descargar un archivo de HDFS y guardarlo en el sistema local, especificando la ruta de origen y destino.Leer un archivo de HDFS:hdfs dfs -cat /logs/app.logEste comando se utiliza para visualizar el contenido de un archivo en HDFS, especificando la ruta del archivo.Borrar un archivo o directorio de HDFS:hdfs dfs -rm -r /tmpEste comando se utiliza para eliminar un archivo o directorio de HDFS, especificando la ruta del archivo o directorio y utilizando la opción -r para eliminar directorios y subdirectorios recursivamente.Ver el espacio utilizado en HDFS:hdfs dfs -du -h /Este comando se utiliza para ver el espacio utilizado en HDFS, utilizando la opción -h para ver los resultados en una unidad legible humanamente.Ver la lista de archivos en un directorio de HDFS:hdfs dfs -ls /documentosEste comando se utiliza para ver una lista de los archivos y directorios en un directorio específico de HDFSVer la información de un archivo en HDFS:hdfs dfs -stat /imagenes/foto1.jpgEste comando se utiliza para ver información detallada sobre un archivo específico en HDFS, como el tamaño, la fecha de modificación y el propietario.Mover un archivo en HDFS:hdfs dfs -mv /docs/informe-hdfs.txt /others/informe-hdfs.txtEste comando mueve el archivo "informe_hdfs.txt" del directorio "/docs" al directorio "/others" en HDFS.Copiar un archivo en HDFS:hdfs dfs -cp /images/foto1.jpg /backup/foto1.jpgEste comando copia el archivo "foto1.jpg" del directorio "/images" al directorio "/backup" en HDFS.Mostrar la configuración de HDFS:hdfs dfsadmin -reportEste comando muestra la configuración actual de HDFS, incluyendo la versión, el número de nodos, el espacio libre y utilizado, entre otros.Es importante recordar que estos son solo algunos ejemplos básicos de cómo interactuar con HDFS utilizando comandos de terminal Linux. HDFS tiene una gran cantidad de funciones y opciones adicionales que pueden ser utilizadas para satisfacer las necesidades específicas de un proyecto. Por ejemplo, se pueden utilizar los comandos "hdfs dfs -chmod" y "hdfs dfs -chown" para cambiar los permisos y propietarios de archivos y directorios en HDFS respectivamente.En conclusión, HDFS es un sistema de archivos distribuido escalable y tolerante a fallos, ideal para almacenar grandes cantidades de datos. Utilizando comandos de terminal Linux se puede interactuar con HDFS de manera sencilla y eficiente, realizando operaciones como subir, descargar, leer, eliminar y modificar archivos y directorios.Además de los comandos mencionados anteriormente, HDFS también ofrece la posibilidad de realizar operaciones más avanzadas como la creación de puntos de montaje, la configuración de políticas de replicación y almacenamiento, y la monitorización del estado del sistema. También es posible utilizar la interfaz web de HDFS, denominada Namenode UI, para realizar operaciones básicas de manera gráfica.Para utilizar HDFS en un proyecto es necesario tener un cluster Hadoop configurado y funcionando. Hay tener en cuenta que algunas operaciones pueden requerir permisos de administrador, por lo que es recomendable tener un usuario con ese rol configurado para realizar dichas tareas.Otro aspecto importante es la configuración de HDFS. Es necesario especificar la dirección del NameNode y configurar la cantidad de bloques y replicas que se usarán en el sistema. Esto se puede hacer mediante el archivo de configuración hdfs-site.xml.Para trabajar con HDFS de manera más eficiente, también se recomienda utilizar herramientas de administración como Ambari o Cloudera Manager. Estas herramientas permiten monitorear el estado del cluster, agregar y eliminar nodos, y realizar operaciones de mantenimiento.
Guía práctica de SQL.
SQL (Structured Query Language) es un lenguaje de programación utilizado para interactuar con bases de datos relacionales. Es un lenguaje estándar y es utilizado por una amplia variedad de sistemas de gestión de bases de datos, incluyendo MySQL, PostgreSQL, Microsoft SQL Server, Oracle y muchos otros.Para comenzar a trabajar con SQL, primero debemos crear una base de datos. Esto se puede hacer con el siguiente comando:create database HelloWorld;Este comando crea una nueva base de datos llamada HelloWorld.Una vez creada la base de datos, podemos ver una lista de todas las bases de datos existentes en el sistema utilizando el comando:show databases;Este comando muestra una lista de todas las bases de datos existentes en el sistema.Para utilizar una base de datos específica, utilizamos el comando use seguido del nombre de la base de datos:use HelloWorld;Este comando selecciona la base de datos HelloWorld para ser utilizada en las siguientes consultas.Una vez que tenemos una base de datos seleccionada, podemos comenzar a crear tablas. Por ejemplo, podemos crear una tabla llamada animals con los siguientes campos: id, kind y state, donde id es la clave primaria:create table animals (Este comando crea una nueva tabla llamada animals con las columnas id, kind y state. La columna id se establece como la clave primaria de la tabla.Podemos modificar una columna existente en una tabla utilizando el comando alter table seguido de modify column, el nombre de la columna y las nuevas especificaciones:
id int,
kind varchar(255),
state varchar(255),
PRIMARY KEY (id)
);alter table animals modify column id int auto_increment;Este comando modifica la columna id de la tabla animals para que sea una columna autoincrementable.Para obtener una descripción detallada de una tabla, podemos utilizar el comando describe seguido del nombre de la tabla:describe animals;Este comando muestra detalles sobre la estructura de la tabla, como nombres de columnas, tipos de datos y si una columna es o no una clave primaria.Una vez que tenemos una tabla creada, podemos insertar registros en ella utilizando el comando insert into seguido del nombre de la tabla y los valores a insertar:
insert into animals (kind, state) values ('gamusino','happy');insert into animals (kind, state) values ('goat', 'crazy');insert into animals (kind, state) values ('bird', 'lazy');Este comando inserta tres registros en la tabla animals con los valores gamusino, happy en la primera fila, goat y crazy en la segunda fila y bird, lazy en la tercera fila.Podemos recuperar registros de una tabla utilizando el comando select seguido del nombre de las columnas que deseamos recuperar y el nombre de la tabla:select \* from animals;Este comando selecciona todos los registros de la tabla animals.Podemos limitar el número de registros que se extraen usando limit:select * from users limit 2;Esta consulta extrae sólo dos registros de la tabla users.También podemos utilizar cláusulas where para filtrar los resultados de una consulta:select \* from animals where state = 'happy';
select \* from animals where state = 'crazy' and kind = 'goat';El primer comando selecciona todos los registros de la tabla animals donde el valor de la columna state es igual a happy y el segundo comando selecciona todos los registros de la tabla animals donde el valor de la columna state es igual a crazy y el valor de la columna kind es igual a goat.Con select se pueden usar condiciones lógicas para filtrar resultados. En lo sucesivo, algunos ejemplos prácticos de ello:La primera consulta, select \* from users where age >= 20 and email = 'paco@test.com';, selecciona todas las columnas (*) de la tabla users donde la edad sea mayor o igual a 20 y el correo electrónico sea igual a paco@test.com.La segunda consulta, select \* from users where age >= 20 or email = 'paco@test.com';, selecciona todas las columnas (*) de la tabla users donde la edad sea mayor o igual a 20 o el correo electrónico sea igual a paco@test.com.La tercera consulta, select \* from users where email != 'paco@test.com';, selecciona todas las columnas (*) de la tabla users donde el correo electrónico sea diferente a paco@test.com.La cuarta consulta, select \* from users where age between 20 and 50;, selecciona todas las columnas (*) de la tabla users donde la edad está entre 20 y 50.La quinta consulta, select \* from users where email like '%test%';, selecciona todas las columnas (*) de la tabla users donde el correo electrónico contenga la cadena test en cualquier lugar.La sexta consulta, select \* from users where email like '%test';, selecciona todas las columnas (*) de la tabla users donde el correo electrónico termine con test.La séptima consulta, select \* from users where email like 'maria%';, selecciona todas las columnas (*) de la tabla users donde el correo electrónico empiece con maria.La octava consulta, select \* from users order by age asc;, selecciona todas las columnas (*) de la tabla users y las ordena por edad en orden ascendente.La novena consulta, select \* from users order by age desc;, selecciona todas las columnas (*) de la tabla users y las ordena por edad en orden descendente.La décima consulta, select max(age) as mayor from users;, selecciona el valor máximo de la columna age y lo renombra como mayor de la tabla users.La undécima consulta, select min(age) as menor from users;, selecciona el valor mínimo de la columna age y lo renombra como menor de la tabla users.También podemos utilizar el comando update para cambiar los valores existentes en una tabla, utilizando la cláusula set para especificar los nuevos valores y la cláusula where para especificar qué registros deben ser actualizados.update animals set state = 'sad' where id = 2;Este comando cambia el valor de la columna state a sad en el registro con id igual a 2 en la tabla animals.Para eliminar registros de una tabla, utilizamos el comando delete seguido del nombre de la tabla y la cláusula where para especificar qué registros deben ser eliminados:delete from animals where id = 3;Este comando elimina el registro con id igual a 3 de la tabla animals.Ahora veremos una serie de consultas SQL más avanzadas que hacen uso de la unión e intersección de tablas así como de funciones de agrupación y filtrado:select u.name, u.email, p.name from users u left join product p on u.id = p.created\_by;, utiliza una operación de left join para seleccionar los nombres, correos electrónicos y nombres de los productos de las tablas users y product donde los IDs correspondan. El left join incluye todas las filas de la tabla users y las filas correspondientes de la tabla product, si existen. Si no existe una correspondencia en la tabla product, los valores de las columnas correspondientes serán NULL.select u.name, u.email, p.name from users u right join product p on u.id = p.created\_by;, utiliza una operación de right join para seleccionar los mismos datos que la primera consulta, pero con la diferencia de que incluye todas las filas de la tabla product y las filas correspondientes de la tabla users, si existen. Si no existe una correspondencia en la tabla users, los valores de las columnas correspondientes serán NULL.select u.name, u.email, p.name from users u inner join product p on u.id = p.created\_by;, utiliza una operación de inner join para seleccionar los mismos datos que la primera consulta, pero solo incluye las filas que tienen una correspondencia en ambas tablas.select u.id, u.name, p.id, p.name from users u cross join product p;, utiliza una operación de cross join para seleccionar el ID, nombre, ID de producto y nombre de producto de cada usuario con todos los productos existentes en la tabla product. Esto genera una tabla cartesiana con todas las combinaciones posibles entre usuarios y productos.select count(id), marca from product group by marca;, agrupa los productos por marca y cuenta el número de productos por marca.select count(id), marca from product group by marca having count(id) > 2;, es similar a la anterior consulta, pero solo selecciona las marcas que tienen más de 2 productos.Y para finalizar drop table product;, elimina la tabla product de la base de datos. Es importante tener precaución al ejecutar esta consulta, ya que todos los datos de la tabla serán eliminados permanentemente.
HIVE desde 0.
Instalación y configuración.
Apache Hive es un software que permite el manejo simple de grandes estructuras de datos mediante comandos SQL. Se usa sobre Hadoop y facilita las tareas enormemente al desarrollador, pues en lugar de usar HDFS directamente (el sistema distribuido de archivos de Hadoop) y tener que correr scripts en java, python o bash para hacer algún tipo de operación, con Hive sólo tiene que hacer una consulta SQL desde la terminal.Para descargar Hive accedemos a la web de Apache:
https://www.apache.org/dyn/closer.cgi/hive/Y seleccionamos el paquete de la última versión o la versión que mejor se adapte al Hadoop que estés utilizando; por ejemplo: para Hadoop 3.3.4 funciona bien la última versión estable: apache-hive-2.3.9-bin.tar.gzTrás la descarga en nuestro Linux (en mi caso una máquina CentOS 7) nos ubicamos en el directorio dónde queramos almacenarlo, por ejemplo:cd /opt/hadoopdescomprimimos el archivo:^tar xvf /home/hadoop/Descargas/apache-hive-2.3.9-bin.tar.gz ^Por simplicidad lo movemos a un directorio llamado hive:mv apache-hive-2.3.9-bin/ hiveSi ahora hacemos un ls -ltr podremos ver al final la carpeta "hive" con todo el contenido.Ahora para poder ejecutar HIVE correctamente y usar sus comandos necesitamos configurar las variables de entorno y el PATH en el .bashrc:nano /home/hadoop/.bashrcUsando un editor de código como por ejemplo nano añadimos:
export HIVE\_HOME=/opt/hadoop/hiveEsta variable de entorno indicará la ruta dónde hemos alojado Hive. También debemos añadir los binarios de Hive al PATH para poder usar sus comandos desde cualquier sitio en la terminal::$HIVE\_HOME/binDe modo que al final el .bashrc se parecerá a esto:
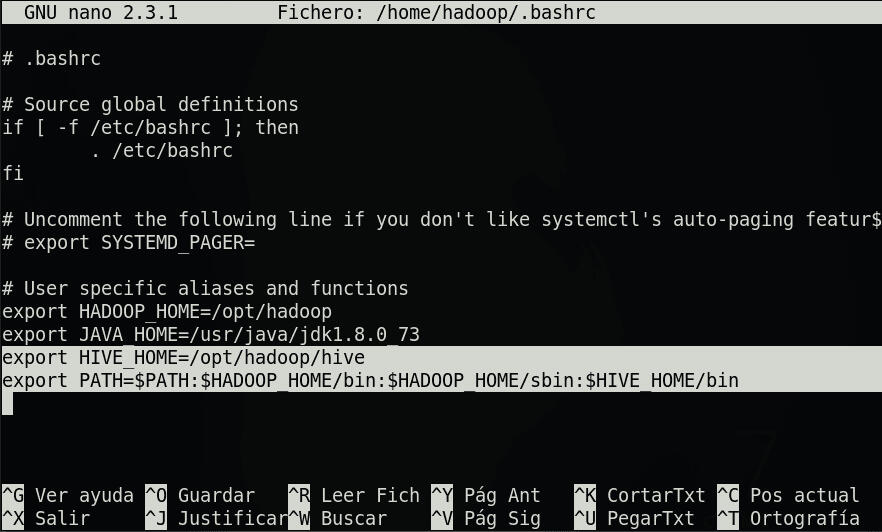
Para empezar a usar HIVE de una manera simple y rápida podemos usar los templates que nos ofrece el propio Hive. Para ello accedemos al directorio que creamos anteriormente:cd /opt/hadoop/hiveSi hacemos un ls veremos el directorio conf accediendo a él cd conf y listando ls veremos una lista de archivos que acaban en .template
Para emepezar a trabajar los copiaremos sin el .template:^cp hive-default.xml.template hive-site.xml^
^cp hive-env.sh.template hive-env.sh^
^cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties^
^cp hive-log4j2.properties.template hive-log4j2.properties^
^cp beeline-log4j2.properties.template beeline-log4j2.properties^Si hacemos ahora un ls -ltr veremos al final de la lista los archivos que acabamos de copiar sin el .template:^-rw-r--r--. 1 hadoop hadoop 401141 ene 10 21:50 hive-site.xml
-rw-r--r--. 1 hadoop hadoop 2274 ene 10 21:53 hive-exec-log4j2.properties
-rw-r--r--. 1 hadoop hadoop 3086 ene 10 21:55 hive-log4j2.properties
-rw-r--r--. 1 hadoop hadoop 1596 ene 10 21:57 beeline-log4j2.properties
-rw-r--r--. 1 hadoop hadoop 2439 ene 10 22:36 hive-env.sh
^
Para que HIVE encuentre las variables de entorno que anteriormente definimos hay que modificar el archivo que acabamos de copiar: hive-env.sh
Para ello ejecutamos nano hive-env.sh y definimos en el archivo las variables:export HADOOP\_HOME=/opt/hadoop
export HIVE\_CONF\_DIR=/opt/hadoop/hive/confFinalmente, puesto que HIVE usa por debajo HDFS, para asegurarnos de su correcto funcionamiento debemos crear un par de ficheros en HDFS (si no existen), estos son: /tmp y /user/hive/warehouse:hdfs dfs -mkdir /tmp
hdfs dfs -mkdir /user/hive/warehouseLe damos permisos para que HIVE pueda acceder a ellos:hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouseNota: Es posible que trás relizar el proceso de instalación y configuración sea necesario detener HDFS y los procesos y reiniciar el cluster, de esta manera se aplicarán los nuevos cambios realizados. Para ello puedes pararlo con stop-dfs.sh (datos) y stop-yarn.sh (procesos) y volver a encenderlo con start-dfs.sh y start-yarn.sh
Bases de datos y tablas en Hive.
Listando los binarios de Hive:ls /opt/hadoop/hive/binVemos varias opciones disponibles:^beeline ext hive hive-config.sh hiveserver2 hplsql metatool schematooll^hive nos permite crear una simple base de datos local Derby.
hiveserver2 nos permite levantar un servidor y conectarnos a él remotamente a través de la herramienta beeline para atacar otras bases de datos más grandes cómo MySQL.Pero antes de esto debemos de añadir las siguientes propiedades al hive-site.xml
que creamos anteriormente:
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>nano /opt/hadoop/hive/conf/hive-site.xml y añadimos las propiedades al inicio del documento.Listo! Ahora podemos empezar a crear nuestras primeras bases de datos. Para ello creamos primero una carpeta que podemos llamar: bd para empezar a trabajar.cd /opt/hadoop/hive/
mkdir dbAhora accedemos a directorio db e inicializamos el esquema de la base de datos que vamos a usar, que en este caso es derby:cd db
schematool -initSchema -dbType derbySi ahora hacemos un ls vemos que se ha creado un fichero de log derby.log y la propia base de datos en metastore_dbEjecutando:create database testing;Veremos que en el directorio warehouse de HDFS se ha creado la base de datos "testing.db". Para comprobarlo podemos abrir otra terminal y ejecutar:hdfs dfs -ls /user/hive/warehouseOtra opción más sencilla para comprobar que nuestra base de datos "testing" se ha creado es ejecutar el siguiente comando en el propio hive:hive> show databases;Y se mostrará la que hemos creado (testing) y otra por defecto: default.
También podemos crear tablas. Vamos a crear una tabla a modo de ejemplo:hive> create table if not exits tableOnePara ver que se ha creado la tabla podemos hacer:
>(
> name string
>);show tables; Y para ver que se ha creado la columna:desc tableOne;A partir de aquí, cómo se indicó con anterioridad, podemos manipular nuestras bases de datos y tablas a través de HIVE haciendo uso de consultas SQL. Para profundizar en esto recomiendo echar un vistazo a la Guía Práctica de SQL.== Tablas internas y externas en HIVE ==Una de las características clave de Hive es la capacidad de crear tablas internas y externas.Una tabla interna en Hive es una tabla que almacena sus datos directamente en el sistema de almacenamiento distribuido HDFS (Hadoop Distributed File System) del cluster. Esto significa que cuando se elimina una tabla interna, los datos también se eliminan del sistema de almacenamiento.Por otro lado, una tabla externa en Hive es una tabla que almacena sus datos en un sistema de almacenamiento externo al cluster, como un sistema de archivos local o una tabla de una base de datos relacional. Si se elimina una tabla externa, los datos permanecen en el sistema de almacenamiento externo, pero ya no se pueden acceder a través de Hive.La principal ventaja de las tablas internas es que son más fáciles de administrar, ya que los datos están almacenados directamente en el cluster, mientras que las tablas externas son útiles cuando se desea utilizar datos existentes en un sistema de almacenamiento externo, o cuando se desea compartir los datos con otras aplicaciones.A continuación, se presentan algunos ejemplos de código para trabajar con tablas internas y externas en Hive:Creación de una tabla interna:CREATE TABLE employees (Creación de una tabla externa:
id INT,
name STRING,
salary FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';CREATE EXTERNAL TABLE employees (Cargar datos en una tabla desde un fichero local ubicado en el Linux:
id INT,
name STRING,
salary FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION '/user/hive/data';LOAD DATA LOCAL INPATH '/home/user/Desktop/employees.txt' INTO TABLE employees;Cargar datos en una tabla desde un fichero ubicado en HDFS:LOAD DATA INPATH '/user/data/employees.txt' INTO TABLE employees;Selección de datos de una tabla interna o externa:SELECT * FROM employees;Eliminar una tabla interna:DROP TABLE employees;Eliminar una tabla externa:DROP EXTERNAL TABLE employees;Estos son solo algunos ejemplos básicos de código y que hay muchas otras operaciones y funcionalidades que se pueden realizar con tablas internas y externas en Hive. Además, es importante tener en cuenta que los parámetros y la sintaxis pueden variar dependiendo de la versión de Hive que estés utilizando.
Conexiones remotas a HIVE.
Dos herramientas propias del ecosistema hadoop que pueden ser utilizadas para conectarte a HIVE de manera remota son: hiveserver2 y beeline.Establecer conexión remota con Hive mediante hiveserver2 y beeline es un proceso sencillo y eficiente para trabajar con grandes conjuntos de datos almacenados en un cluster Hive.Para empezar, es necesario tener acceso a un servidor Hive que ejecute hiveserver2. Es posible descargar e instalar hiveserver2 en un servidor local o utilizar una plataforma en la nube como Amazon EMR.Una vez que se tiene acceso al servidor, se puede utilizar beeline, una herramienta de línea de comandos, para establecer una conexión con el servidor y ejecutar consultas Hive. Beeline se puede descargar e instalar en el sistema local.Para establecer una conexión con hiveserver2 utilizando beeline, se utiliza el siguiente comando:beeline -u "jdbc:hive2://<host>:<port>/<database>" -n <username> -p <password>En este comando, se debe reemplazar <host> con la dirección IP o el nombre de host del servidor Hive, <port> con el puerto en el que se está ejecutando hiveserver2 (por defecto es 10000), <database> con el nombre de la base de datos en la que se desea conectarse y <username> y <password> con las credenciales de inicio de sesión del usuario.Una vez que se establece la conexión, se puede ejecutar consultas Hive utilizando la sintaxis de SQL estándar. Además, beeline también ofrece una serie de comandos específicos para realizar tareas adicionales, como mostrar las tablas existentes en una base de datos, descargar resultados de consultas en un archivo, etc.
Sqoop = DDBBs + Hadoop
Sqoop es una herramienta open source que se utiliza para la integración de datos entre bases de datos relacionales y Hadoop. Sqoop permite transferir grandes volúmenes de datos de manera eficiente y sin tener que escribir código complejo. Además es una pieza clave en el ecosistema Hadoop y se integra perfectamente con otros componentes, como Hive.1. Instalación y configuración de Sqoop.La configuración de Sqoop es sencilla y se puede realizar a través de la línea de comandos. Primero, debemos descargar, instalar y configurar Sqoop en nuestro sistema siguiendo las especificaciones que se describen en la página oficial de Apache. A continuación, debemos configurar la conexión con la base de datos relacional utilizando los siguientes comandos:sqoop list-databasesDonde hostname es el nombre del host de la base de datos, database es el nombre de la base de datos, user es el nombre de usuario y pass es la contraseña.2. Importar datos a HDFSUna vez que se ha establecido la conexión, podemos importar los datos a Hadoop utilizando el siguiente comando:
--connect jdbc:mysql://hostname/database
--username user
--password passsqoop importDonde table_name es el nombre de la tabla que se desea importar, /user/sqoop_import/table_name es la ruta de destino en el sistema de archivos HDFS.3. Verificar los datos importadosUna vez que se han importado los datos a HDFS, puede verificar su existencia mediante el siguiente comando de Hadoop:
--connect jdbc:mysql://hostname/database
--username user
--password pass
--table table\_name
--target-dir /user/sqoop\_import/table\_namehdfs dfs -ls /path/to/hdfsEl comando anterior mostrará una lista de los archivos importados en el directorio especificado en el paso 2.4. Exportar datos desde HDFS.Además de importar datos de una base de datos externa a HDFS, también puede exportar datos desde HDFS a una base de datos externa. Para hacer esto, utilice el siguiente comando de Sqoop:sqoop exportEn el comando anterior, reemplace <hostname>, <database-name>, <username>, <password> y <table-name> con sus valores específicos. En <port> se debe especificar el número de puerto por el que se va a establecer la conexión. También especifique el directorio en HDFS desde donde se exportarán los datos mediante --export-dir.6. Verificar los datos exportadosUna vez que se han exportado los datos a la base de datos externa, puede verificar su existencia mediante una consulta a la base de datos.En conclusión: Sqoop es una herramienta valiosa para conectar HDFS con una base de datos externa. Con estos sencillos pasos, puede importar y exportar datos de manera eficiente y fácil. Sin embargo, es importante tener en cuenta que los detalles específicos de la configuración pueden variar dependiendo de la base de datos y el sistema en uso. Por lo tanto, es recomendable consultar la documentación de Sqoop y la base de datos en cuestión para obtener información más detallada y específica.Si necesita profundizar en el uso de comandos más avanzados puede echarle un vistazo a este Blog.
--connect jdbc:mysql://<hostname>:<port>/<database-name>
--username <username>
--password <password>
--table <table-name>
--export-dir /path/to/hdfs
Cluster de Alta Disponibilidad.
Zookeeper y la Alta Disponibilidad en sistemas distribuidosZookeeper es un componente fundamental en el ecosistema Apache Hadoop, que ayuda a garantizar la alta disponibilidad y la coordinación de las aplicaciones distribuidas. Este artículo profundizará en la importancia de Zookeeper y cómo se utiliza para lograr la alta disponibilidad en un entorno de Big Data.Antes de entrar en detalles sobre Zookeeper, es importante comprender el concepto de alta disponibilidad. La alta disponibilidad se refiere a la capacidad de un sistema para mantenerse en funcionamiento y proporcionar servicios sin interrupción, incluso en caso de fallas en los componentes individuales. Esto es esencial en entornos de Big Data, donde se manejan grandes cantidades de datos y es importante garantizar la continuidad del servicio.Zookeeper es un sistema de coordinación de código abierto diseñado específicamente para garantizar la alta disponibilidad en entornos distribuidos. Se utiliza comúnmente en aplicaciones que requieren la coordinación de múltiples componentes, como el equilibrio de carga, la sincronización de procesos y la gestión de configuraciones.Funcionamiento de Zookeeper y consistencia en tiempo realEste software funciona sobre un clúster de nodos, que son servidores independientes que se comunican entre sí. Cada nodo mantiene una copia de la información orquestada por Zookeeper y se comunica constantemente con los demás nodos para mantener la consistencia de la información. En caso de falla de un nodo, otro nodo tomará el control y mantendrá el servicio sin interrupciones.Una de las principales características de Zookeeper es su capacidad para mantener la consistencia de la información en tiempo real. Cada nodo mantiene un registro de los cambios realizados en la información almacenada y los sincroniza con los demás nodos en tiempo real. Esto garantiza que, en caso de falla de un nodo, la información más reciente esté disponible en otro nodo y se pueda continuar el servicio sin interrupciones.Además, Zookeeper permite la implementación de patrones de distribución comunes, como el equilibrio de carga y la sincronización de procesos. Estos patrones pueden ser implementados de manera sencilla y eficiente mediante el uso de las API de Zookeeper.Implementación de Zookeeper en su solución de Big Data1 Instale y configure Zookeeper en un clúster de nodos.2 Cree una estructura de árbol de zookeeper y almacene la información en los nodos del clúster.3 Utilice las API de Zookeeper para implementar patrones de distribución comunes, como el equilibrio de carga y la sincronización de procesos.4 Monitoree constantemente el estado del clúster de Zookeeper y realice pruebas de failover para garantizar la alta disponibilidad.
Spark, Scala y HDFS
Apache Spark es un marco de cálculo distribuido de alto rendimiento que permite el procesamiento masivo de datos. Está diseñado para manejar grandes cantidades de datos en paralelo y ofrece una amplia gama de herramientas para el análisis y la manipulación de datos. Scala es un lenguaje de programación de alto nivel que se ejecuta en la JVM y es compatible con Spark. En este artículo, exploraremos cómo trabajar con Spark y Scala para procesar grandes cantidades de datos y a configurar de manera sencilla Spark en un cluster Hadoop.
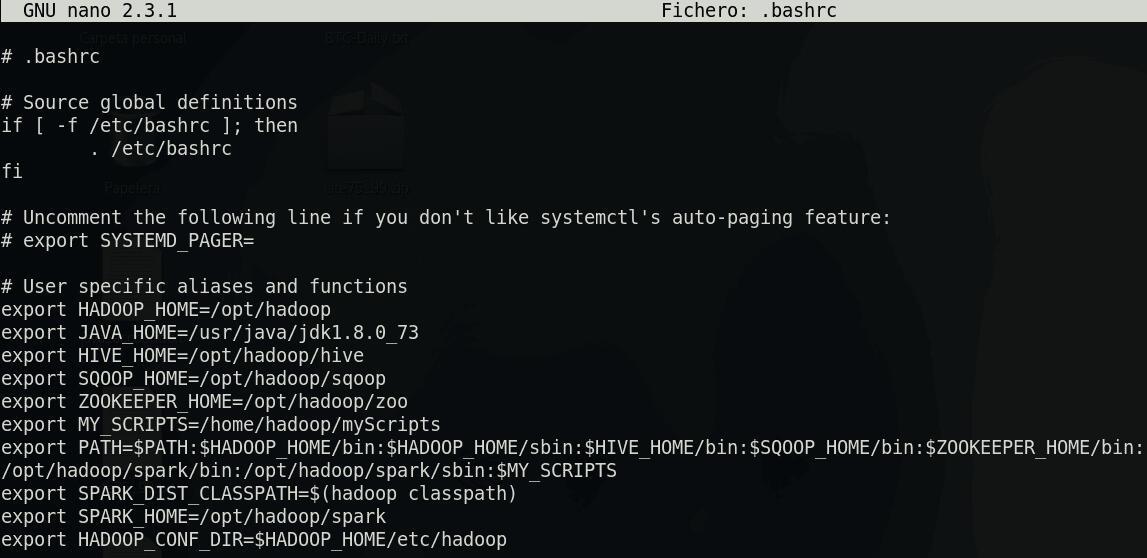
Cluster con Spark y HDFSEn esta sección aprenderemos a configurar de manera sencilla Spark en un cluster de nodos Hadoop para obtener una solución Big Data completa: Procesamiento Distribuido (con Spark) y Almacenamiento Distribuido (con HDFS).Para comenzar, bajo la premisa de que disponemos de un cluster de servidores con Hadoop y HDFS bien configurados, debemos descargar Spark de la página oficial: https://spark.apache.org/downloads.htmlSeleccionaremos la versión: Pre-built with user-provided Apache Hadoop.Una vez descargado en una de nuestras máquinas Linux vamos a configurarlo en uno de los nodos y después lo transmitiremos al resto.Nos ubicamos en el directorio dónde queramos instalarlo cd /tu-ruta y descomprimimos el archivo con:tar xvf /ruta-descarga/spark-3.2.3-bin-without-hadoop.tgzPara trabajar más cómodamente en la terminal podemos cambiar el nombre del directorio spark-3.2.3-bin-without-hadoop a spark:mv spark-3.2.3-bin-without-hadoop/ sparkAhora lo que haremos será acceder al .bashrc cd; nano .bashrc y añadir al PATH la ruta de los binarios de Spark :/tu-ruta/spark/bin y :/tu-ruta/spark/sbin para que sus comandos sean accesibles desde cualquier directorio. También incluiremos la variable:
export SPARK\_DIST\_CLASSPATH=$(hadoop classpath)
Esto permitirá a Spark acceder a las librerías de Hadoop. Por último añadimos el home de Spark:
export SPARK_HOME=/tu-ruta/spark y
export HADOOP\_CONF\_DIR=$HADOOP\_HOME/etc/hadoop
De esta manera Spark podrá encontrar los archivos de configuración de Hadoop.
Al final tu .bashrc se parecerá a esto:
Para que estos cambios tengan efecto podemos recargar el fichero haciendo:
. ./.bashrcSi tenemos, por ejemplo, una conexión SSH configurada entre nuestros nodos podemos copiar directamente este .bashrc y el directorio de spark al resto de nodos mediante:scp .bashrc <nodo X>:/home/<user>
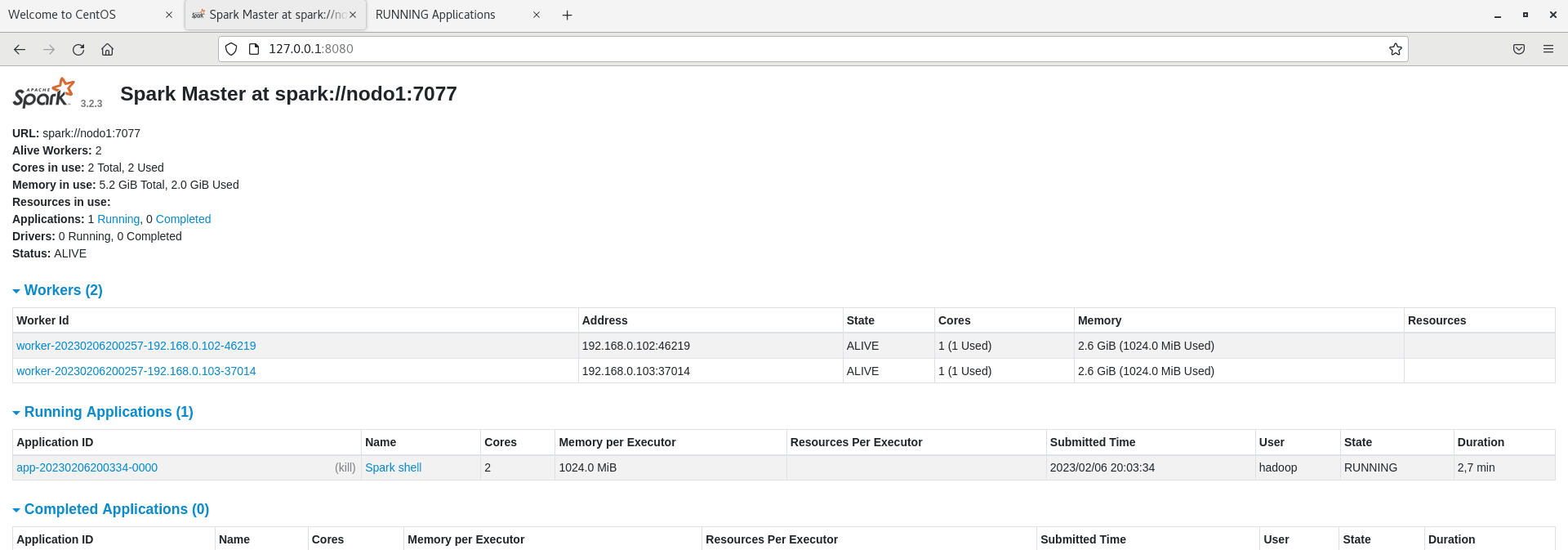
scp -r spark <nodo X>:/tu-ruta De esta manera no tendremos que repetir todo lo anterior en cada nodo.Arrancando SparkEn aras de hacer el proceso lo más sencillo posible, dejaremos la configuración default de Spark, pero es necesario saber que en un entorno real conviene ajustar los archivos de configuración de acuerdo a la estructura de nuestro cluster y a las necesidades de procesamiento.La arquitectura de Spark Master-Worker consiste en una estructura distribuida en la que existe un nodo principal, conocido como el "Master", que coordina y distribuye las tareas a varios nodos llamados "Workers". Cada trabajador tiene la responsabilidad de realizar una tarea específica y de devolver los resultados al nodo maestro. Este enfoque permite a Spark procesar grandes cantidades de datos de manera eficiente, utilizando la capacidad de cálculo combinada de todos los nodos trabajadores.Para arrancar el Master en un nodo (nodo1) ejecutamos: start-master.sh Por defecto este Master estará disponible en spark://nodo1:7077 y si disponemos de un servidor con interfaz gráfica podremos ver la GUI del Master en el localhost: 127.0.0.1:8080
Para arrancar un Worker accedemos a otro nodo, por SSH por ejemplo, y ejecutamos:start-worker.sh --master spark://nodo1:7077Con ** --master spark://nodo1:7077** le indicamos la dirección del Master.
Así podríamos ir arrancando los workers que necesitemos en todos nuestros servidores. Pero ¿Qué ocurre si nuestro cluster tiene cientos de nodos?Si nuestro cluster es muy grande, en lugar de arrancar manualmente los Workers, debemos añadir la lista de hosts al archivo de configuración de Spark llamado "workers". Con esto conseguiremos arrancar un worker en cada nodo que hayamos añadido al archivo con tan sólo ejecutar un script.Para ello accedemos al siguiente directorio:cd /tu-ruta/spark/conf; lsVeremos que hay un archivo llamado workers.template. Lo copiamos sin el .template:cp workers.template workersAccedemos a él nano workers y añadimos la lista de hosts dónde queremos que corran nuestros Workers.Una vez hecho esto y estando arrancado el Master en un nodo, ejecutamos:start-workers.shY así arrancará un Worker en cada nodo.Lanzar aplicaciones con SparkUna vez tenemos el cluster en funcionamiento podemos lanzar contra él aplicaciones o programas para que Spark los ejecute de manera distribuida en paralelo.Por ejemplo, si queremos lanzar la shell de Spark que funciona con Scala ejecutamos:spark-shell --master spark://nodo1:7077Y dentro de ella podremos trabajar con código scala desde la terminal. Si no le indicamos el --master ejecutará los procesos en local.Otra tarea típica sería la de lanzar nuestro propio script, en python por ejemplo, contra el cluster a través de spark. Para ello ejecutamos:spark-submit --master spark://nodo1:7077 --deploy-mode cluster --name <nombre_proceso> <tu-script.py> /directorio/para/la/lectura/de/datos /directorio-de-salidadónde --deploy-mode clsuter indica que se va a lanzar en todo el cluster. Si no se le indica por defecto lo ejecuta en local.
HBase: NoSQL Distribuido
En la era de los datos masivos, es importante contar con herramientas capaces de manejar y procesar grandes cantidades de información en tiempo real. HBase es una de estas herramientas, un sistema de gestión de datos, NoSQL, distribuido, de código abierto y diseñado para satisfacer las necesidades de las aplicaciones que requieren un acceso rápido y preciso a los datos.Funcionando sobre el sistema de archivos Hadoop (HDFS), HBase permite el almacenamiento de datos no estructurados en un formato de tablas organizadas en filas y columnas. Con un modelo altamente escalable y tolerante a fallos, HBase garantiza la disponibilidad y la durabilidad de los datos, y permite la replicación de los mismos en múltiples nodos para asegurar la continuidad del servicio.Además, HBase ofrece una potente indexación de las filas y el acceso a ellas por medio de una clave de fila, lo que lo hace ideal para aplicaciones que requieren una alta tasa de lectura y escritura. En este artículo, exploraremos los comandos más comunes para empezar a trabajar con esta base de datos.Creación de una tabla:Antes de poder agregar datos a HBase, debemos crear una tabla. Para hacer esto, abrimos un terminal y accedemos a la consola HBase (hbase shell). Luego, escribimos el siguiente comando:hbase(main):001:0>Agregar datos a una tabla:Una vez que se ha creado una tabla, podemos agregar datos a ella. Para hacer esto, escribimos el siguiente comando:
create 'nombre\_de\_la\_tabla', 'familia\_de\_columnas'put 'nombre\_de\_la\_tabla',Consultar datos de una tabla:
'fila', 'familia\_de\_columnas:columna', 'valor'get 'nombre\_de\_la\_tabla', 'fila'Eliminar una tabla:Si queremos eliminar una tabla, debemos desactivarla y luego eliminarla. Para hacer esto, escribimos los siguientes comandos:disable 'nombre\_de\_la\_tabla'
drop 'nombre\_de\_la\_tabla'Escanear una tabla:Para escanear una tabla completa, podemos utilizar el siguiente comando:scan 'nombre\_de\_la\_tabla'Escanear un rango de filas:Si deseamos escanear un rango específico de filas, podemos utilizar el siguiente comando:
scan 'nombre\_de\_la\_tabla', {STARTROW => 'fila\_inicio', ENDROW => 'fila\_fin'}Escanear una familia de columnas específica:scan 'nombre\_de\_la\_tabla',Escanear una columna específica:
{COLUMNS => 'familia\_de\_columnas'}scan 'nombre\_de\_la\_tabla',Eliminar una columna específica:
{COLUMNS => 'familia\_de\_columnas:columna'}delete 'nombre\_de\_la\_tabla',Agregar una columna con un tiempo de vida:Si deseamos agregar una columna con un tiempo de vida específico, podemos utilizar el siguiente comando:
'fila', 'familia\_de\_columnas:columna' put 'nombre\_de\_la\_tabla',Estos son solo algunos de los comandos básicos de HBase. Hay muchos otros comandos y opciones disponibles que permiten una gran cantidad de flexibilidad y control sobre las tablas de HBase. Es importante explorar la documentación oficial y los recursos en línea para obtener más información sobre las opciones y las capacidades de HBase.
'fila', 'familia\_de\_columnas:columna',
'valor', ttl => tiempo\_en\_segundos
Deep Learning & Artificial Intelligence
En esta sección podrás encontrar contenido en vídeo, podcasts y código relacionado con las Redes Neuronales y la Inteligencia Artificial. Desde la base hasta los modelos más potentes desarrollados en Python con librerías como Tensorflow 2, Keras o PyTorch... y sus aplicaciones.
El objetivo final será crear máquinas capaces de tomar decisiones y operar de manera autónoma en los mercados financieros.
The Quant's Blog
The Quant's Blog pretende ser un cuaderno de bitácora de las finanzas cuantitativas dónde explicaré ciertas investigaciones, estrategias e ideas. Espero que te sea útil:

Code
Te presento aquí algunos ejemplos de código python para iniciarte en el mundo de las finanzas cuantitativas y el trading algorítmico bajo el prisma de la inteligencia artificial.⚠️Disclaimer: Los algoritmos de selección óptima y mejor combinación pueden introducir overfitting. Si los usa, asegúrese de implementar un sistema para corregir el sesgo de selección, el sobreajuste en el backtest y la no normalidad para garantizar la robustez del modelo.
Se trata de código de ejemplo con fines didácticos. Bajo ninguna circunstancia ponga estos modelos en producción porque la probabilidad de perder dinero es demasiado alta.
| Tech | Concepto | Fecha | Tipo |
|---|---|---|---|
| Deep Neural Network | Time Series Forecasting with DNN | 10/04/2022 | Colab Notebook |
| Deep Neural Network | Automated creation of DNNs | 10/04/2022 | Colab Notebook |
| Deep Neural Network | DNN Bagging & Backtesting | 10/04/2022 | Colab Notebook |
| Recurrent Neural Network | Time Series Forecasting with RNN | 11/04/2022 | Colab Notebook |
| Recurrent Neural Network | Automated creation of RNNs | 11/04/2022 | Colab Notebook |
| Recurrent Neural Network | RNN Bagging & Backtesting | 11/04/2022 | Colab Notebook |
| Deep Temporal Transformer | Time Series Forecasting with DTT | 11/04/2022 | Colab Notebook |
| Deep Temporal Transformer | Automated creation of DTTs | 11/04/2022 | Colab Notebook |
| Deep Temporal Transformer | DTT Bagging & Backtesting | 11/04/2022 | Colab Notebook |
| Hybrid Model | DTT + RNN | 11/04/2022 | Github |
| Reinforcement Learning | --- | Próximamente | Sin Publicar |
| Transfer Learning | --- | Próximamente | Sin Publicar |
| Fine Tuning | --- | Próximamente | Sin Publicar |
| ... | ... | ... | ... |
The Quant's Blog

Hipótesis espectral del mercado
Hipótesis espectral del mercado
En el estudio de los mercados financieros, la complejidad de las series temporales y la naturaleza multifacética de las dinámicas de precios ha llevado a la formulación de diversas teorías y modelos que buscan capturar y predecir su comportamiento. Una nueva perspectiva, que aquí propongo, es la Hipótesis Espectral del Mercado, la cual ofrece una analogía fascinante con la física, particularmente con la naturaleza ondulatoria de la luz.En la física, la luz blanca puede descomponerse en su espectro de colores a través de un prisma, revelando las distintas longitudes de onda que la componen. De manera análoga, la Hipótesis Espectral del Mercado sugiere que los movimientos del mercado, vistos como una serie temporal, pueden descomponerse en distintos segmentos o regímenes de mercado, cada uno con sus propias características y "frecuencias". Estos regímenes pueden representar diferentes tendencias, ciclos o patrones de volatilidad, y su combinación daría como resultado el comportamiento observable del mercado en su totalidad.

Imagen 1: Dispersión de la luz a través de un prisma.
Esta visión espectral del mercado no solo ofrece una forma innovadora de analizar y entender los movimientos de precios, sino que también abre nuevas posibilidades para el desarrollo de herramientas de inversión y estrategias de gestión de riesgos. Al descomponer el mercado en sus componentes fundamentales, es posible identificar patrones ocultos, prever cambios en las condiciones del mercado y, en última instancia, obtener una comprensión más profunda de las fuerzas que impulsan el comportamiento financiero.
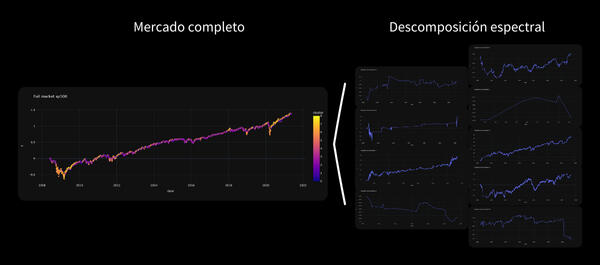
Imagen 2: Dispersión del mercado a través de un algoritmo.
Para ilustrar esto utilizaremos un algoritmo de segmentación o clusterización de datos típico en el campo del Machine Learning: K-Means.
Su propósito principal es dividir un conjunto de datos en k grupos o clusters de manera que los elementos dentro de un mismo grupo sean más similares entre sí que a los de otros grupos. Vamos a descomponer de esta manera el SP500.En las siguiente gráfica se muestra el resultado de la descomposición: un espectro dónde aparecen del mismo color los retornos asociados a cada cluster, segmento o régimen de mercado.
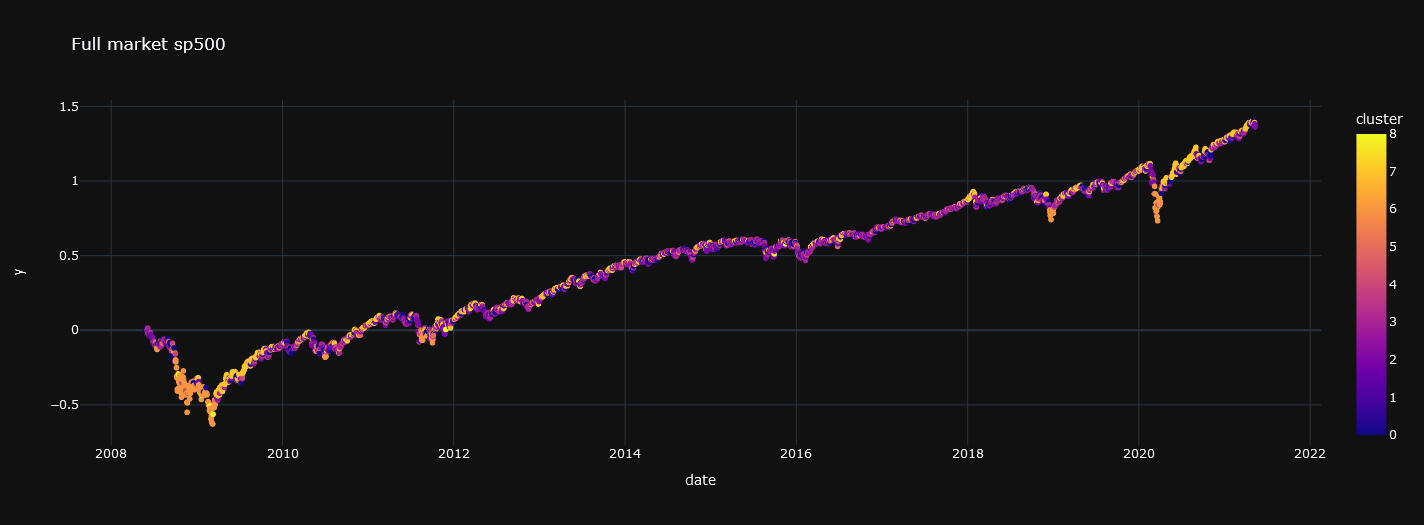
Gráfica 1: Serie temporal con los retornos diarios acumulados del SP500 (conjunto de entrenamiento)
El dataset con información relativa al precio y volumen del índice bursátil estará dividido en dos partes: la de entrenamiento (con el 80% de los datos) y la de testing (con el 20% de los datos)
En este caso se ha obtenido que el número óptimo de segmentos según el método del codo es 9:
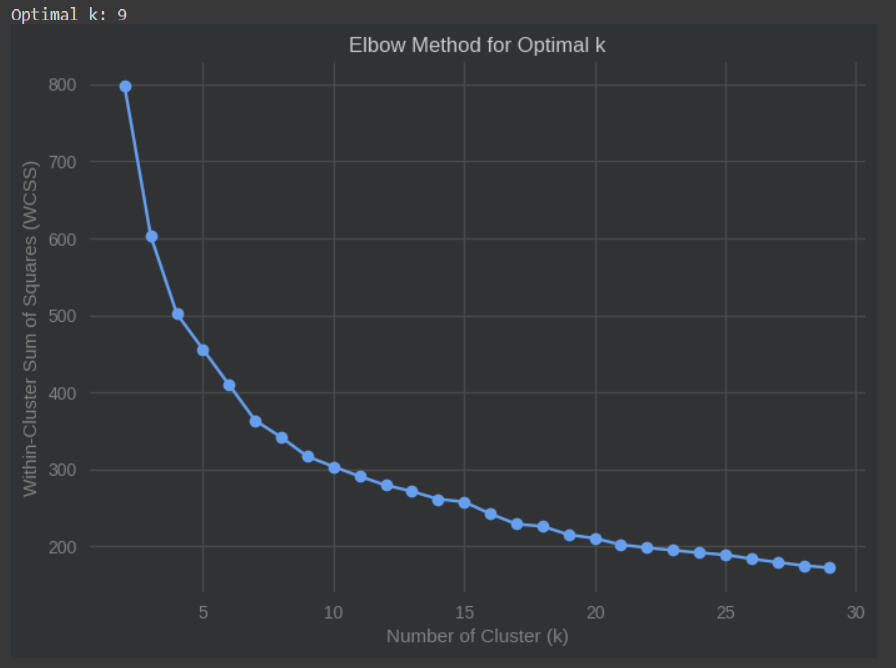
Gráfica 2: Gráfica de codo.
Si representamos cada uno de los segmentos obtenidos en el conjunto de entrenamiento observaremos que existen series dónde la tendencia es claramente alcista, bajista o lateral por no tener una dirección definida en este último caso. Veamos un ejemplo de cada caso:
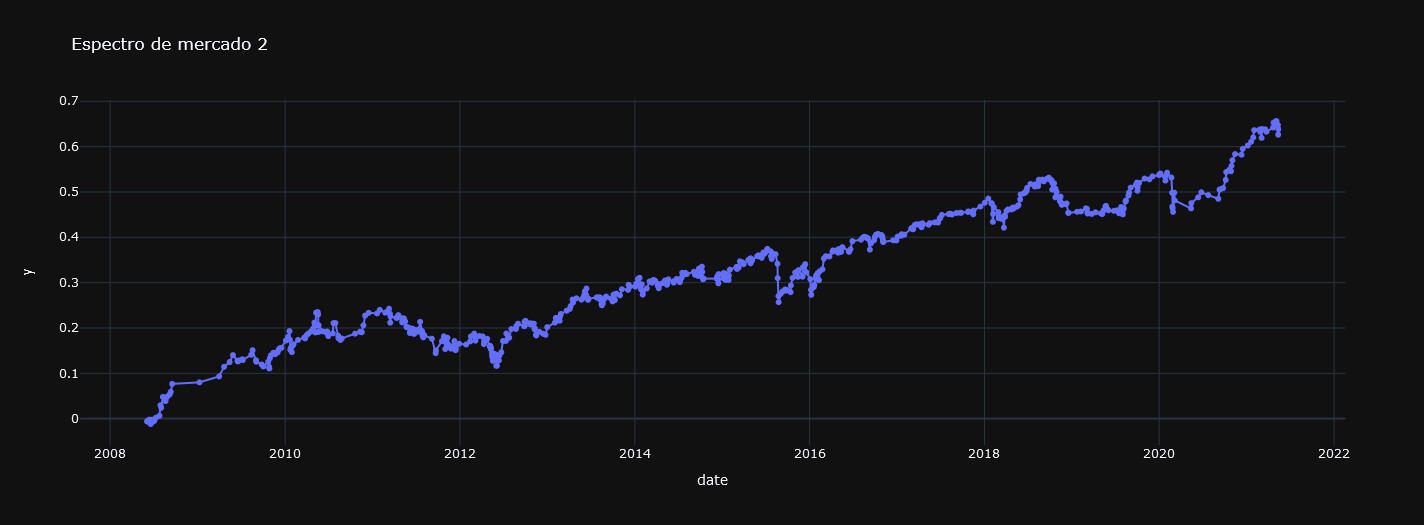
Gráfica 3: Segmento 2, con tendencia alcista.
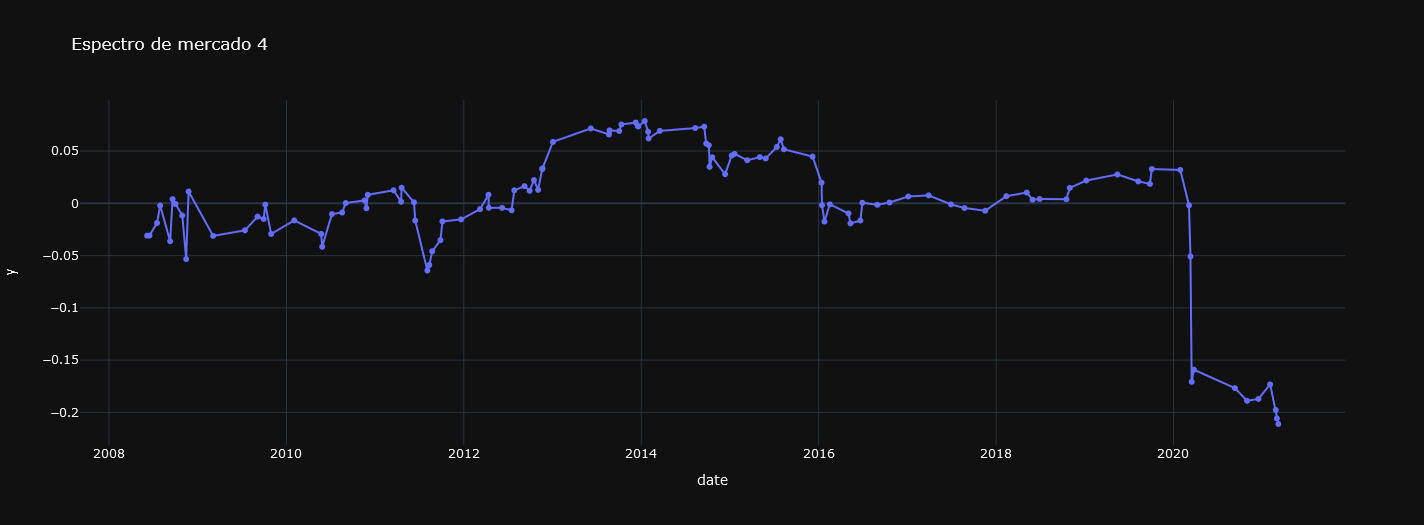
Gráfica 4: Segmento 4, con tendencia lateral.
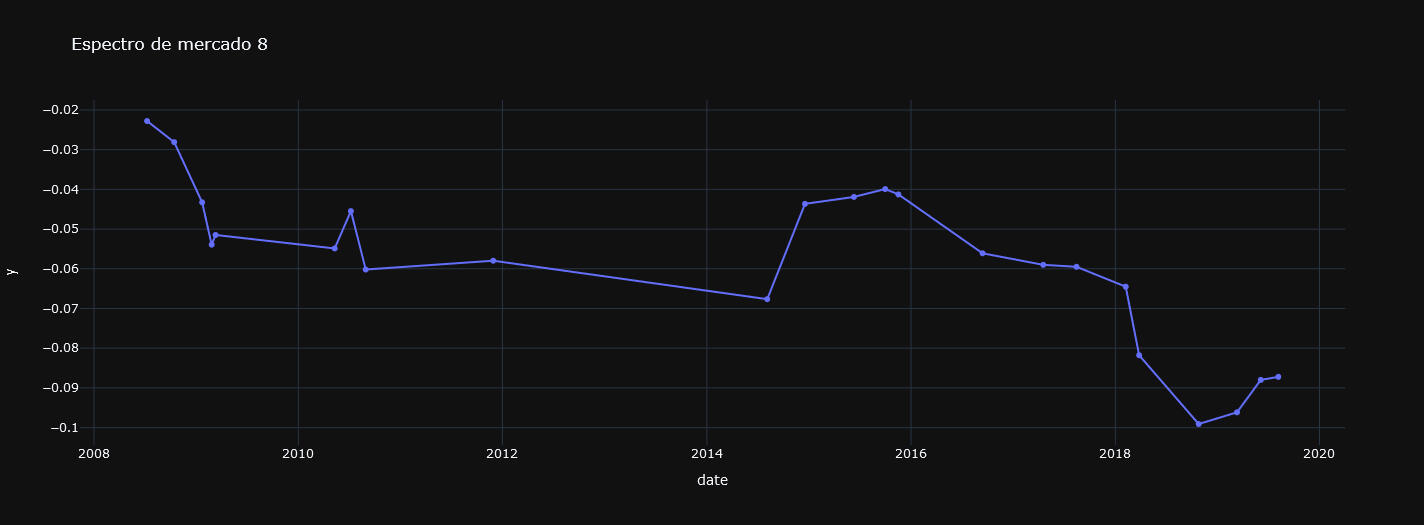
Gráfica 5: Segmento 8, con tendencia bajista.
Ahora que tenemos un modelo capaz de identificar a qué segmento corresponde cada dato o día financiero y sabemos que retornos se suelen dar al día siguiente (que es lo que se ha representado en las gráficas) podemos elaborar una estrategia simple:
Largos en días asociados a clusters con esperanza matemática del retorno diario positiva.
Y cortos en días asociados a clusters con esperanza matemática negativa.
Es decir, comprar en tendencias alcistas o laterales y vender en bajistas.
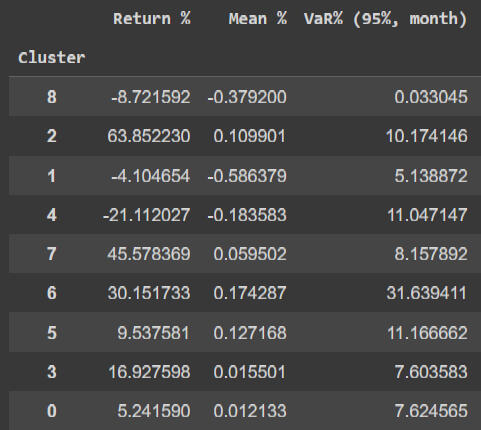
Tabla 1: Retornos, esperanzas matemáticas y VaRs asociados a cada segmento o cluster.
Esta estrategia representa una "recomposición espectral" porque hemos recompuesto el espectro de segmentos de acuerdo al criterio del signo de la esperanza matemática. Dicho de una manera simple: nos quedamos con las tendencias alcistas y laterales y le damos la vuelta a las bajistas. Veamos el resultado de la recomposición sobre los datos de entrenamiento:
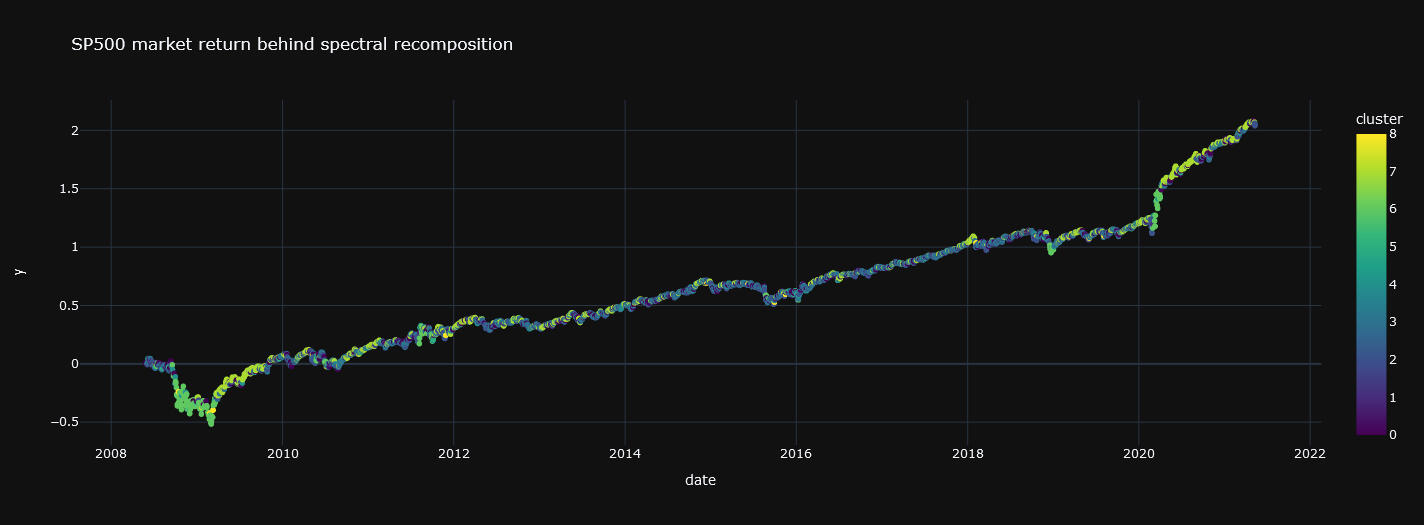
Gráfica 6: Serie temporal con los retornos diarios acumulados del SP500 trás la recomposición espectral (conjunto de entrenamiento)
Se puede observar que se llega a un rendimiento acumulado del 200% mientras que el SP500, sin aplicar esta estrategia, logra menos de un 150% (gráfica 1). Llama la atención el gran rendimiento que consigue en la crisis del covid.Dado que esta simple estrategia bate al mercado en el conjunto de entrenamiento el siguiente paso natural es ver si lo hace para datos que el modelo no conoce, es decir, en el conjunto de testing:
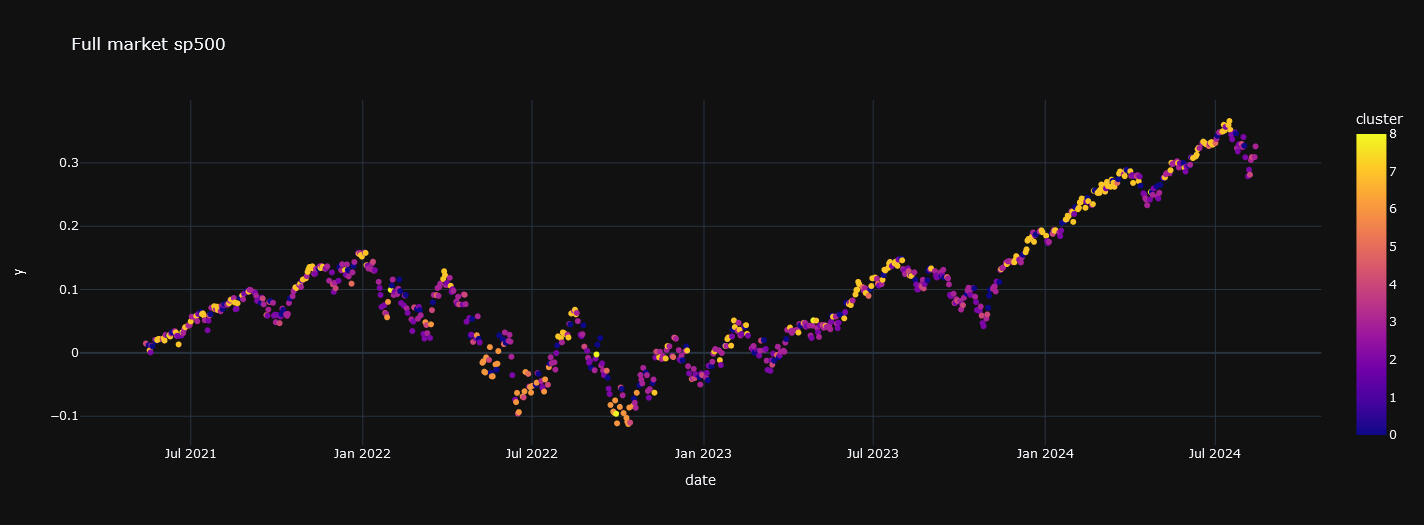
Gráfica 7: Serie temporal con los retornos diarios acumulados del SP500 (conjunto de testing)
Aplicando la estrategia a este conjunto de testing se obtiene:
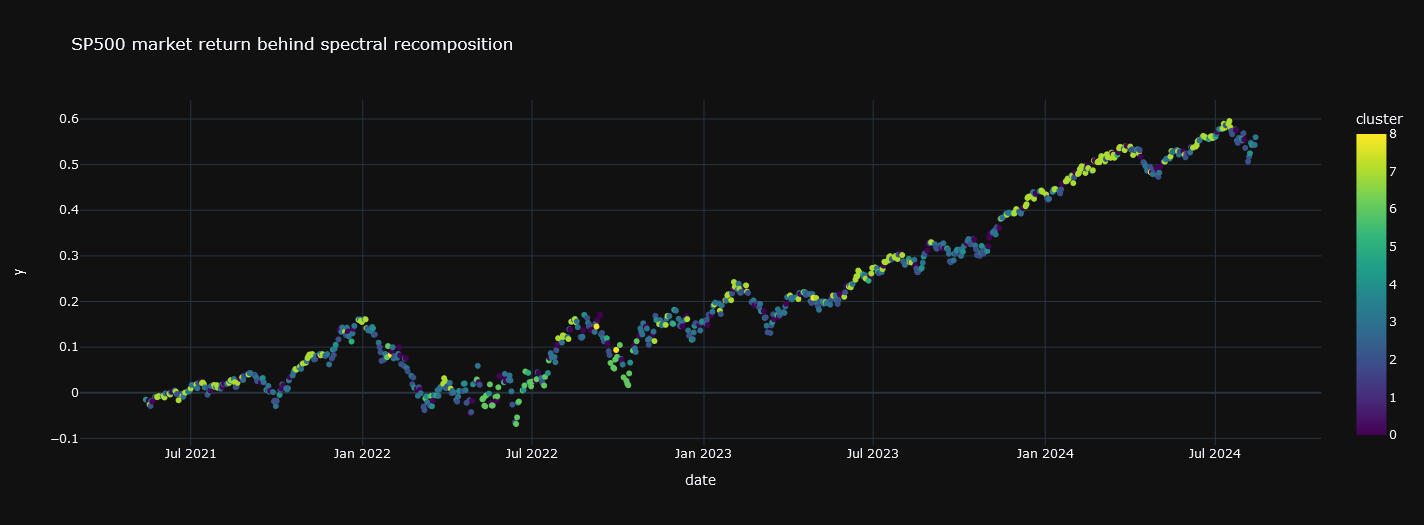
Gráfica 8: Serie temporal con los retornos diarios acumulados del SP500 trás la recomposición espectral (conjunto de testing)
Vemos que esta estrategia reduce la volatilidad en las caídas y prácticamente duplica el rendimiento de su benchmark: el SP500.Veamos más información estadística de la estrategia:
Esperanza matemática del retorno diario del modelo Híbrido: 0.0686 %
Pérdida media cuando pierde: -0.78 %
Ganancia media cuando gana: 0.81 %
Probabilidad de acierto: 53.49 %
Probabilidad de fallo: 46.51 %
Rentabilidad Final: 56.01 %
Ratio riesgo-beneficio: 1.03
Máxima pérdida en un día: -4.32 % => 2022-09-13 00:00:00
Máxima ganancia en un día: 5.54 % => 2022-11-10 00:00:00
Nº máximo de días en negativo: 7
Pérdida media acumulada en 7 días: -5.45 %
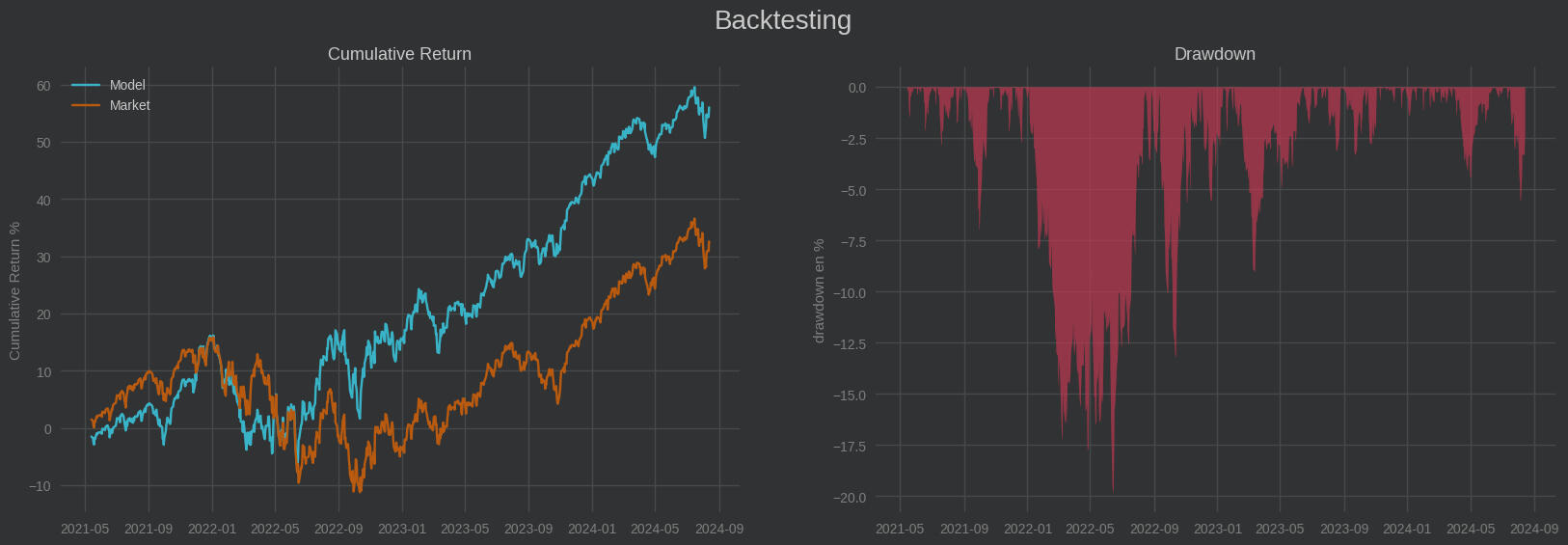
Sortino: 1.487
Beta: 0.79
Alpha: 3.633 %
MaxDrawdown: 19.81 %
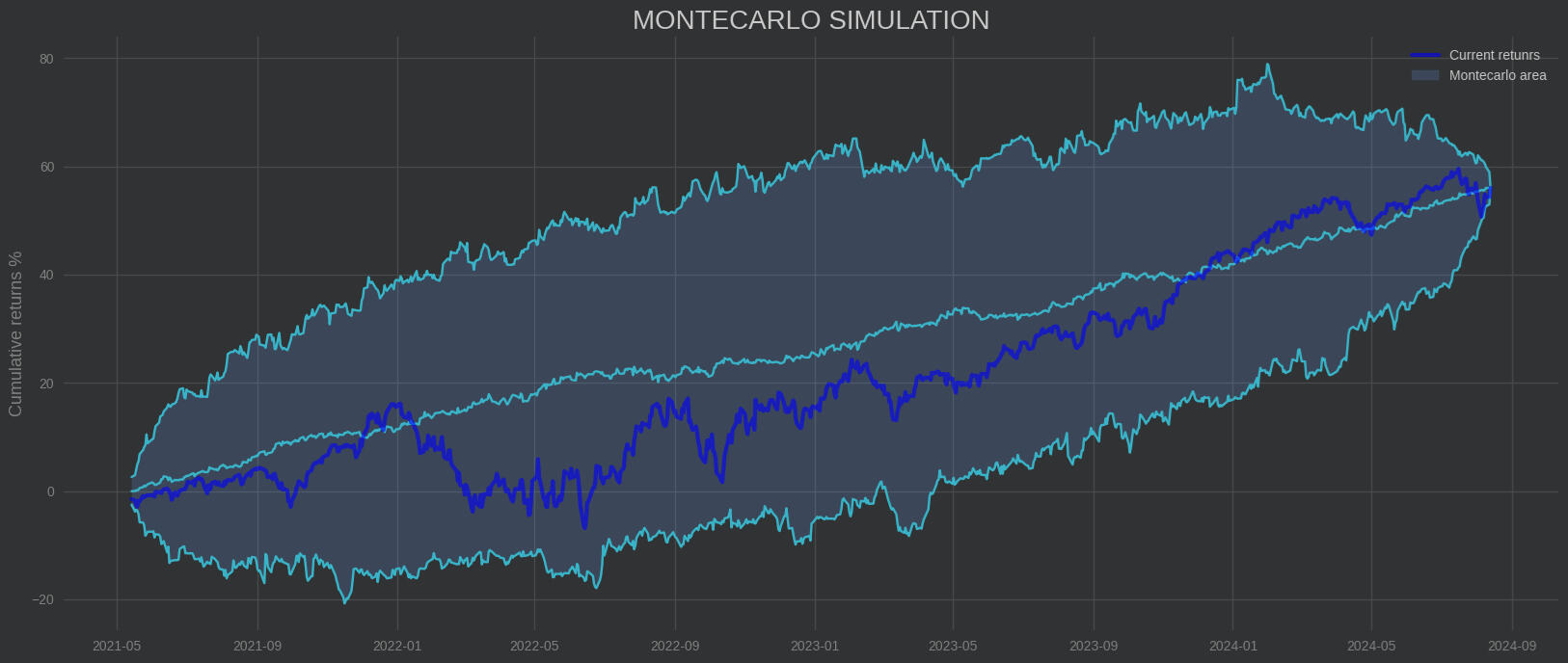
Trás este breve backtest podemos concluir que si bien no es una estrategia super rentable de trading algorítmico, esta hipótesis espectral del mercado materializada mediante un modelo K-Means constituye una buena manera de rentabilizar el capital batiendo al mercado.Recuerda que este artículo resume de manera simplista una idea con fines didácticos y que no es una recomendación de inversión. Para poner en producción con capital real un modelo así hay que llevar a cabo antes un análisis más exahustivo que el aquí expuesto.Un saludo y muchas gracias por tu tiempo!

El poder del BLOCKCHAIN
La descentralización de la información está jugando un papel clave en el desarrollo de la sociedad y la economía. Y la tecnología detrás de esta revolución es el Blockchain.
En esta sección encontrarás todo el conocimiento necesario para convertirte en un experto del Blockchain, las Finanzas Descentralizadas (DeFi), y el mundo Crypto. En las publicaciones cubriremos gradualmente todos los aspectos desde la base hasta los conceptos más avanzados y actuales de las cadenas de bloques, la criptografía, las criptomonedas, los smart contracts y mucho más... Juan Miguel Martos
What is DesoNoCode?
Imagine being able to create websites based on Distributed Ledger Technology (DLT) with drag and drop tools.Now stop imagining because this is precisely what we do at desonocode.com
From greenlight.digital we have launched this project to empower entrepreneurs to create incredible Dapps connected to the Decentralized Social Blockchain (DeSo).DeSo is a new layer-1 blockchain built from the ground up to scale decentralized social applications to one billion users.We have also developed integrations with Arweave, the blockchain that allows you to permanently store the images associated with the NFTs that are created, for example, from your website.At DeSoNoCode Institute we advise you and give you access to blockchain tools without code, Bubble.io templates, plugins, databases and much more. A true web3 arsenal so you can become a successful cryptopreneur without coding anything.
Juan Miguel Martos
¿Qué es el Blockchain?
El término Blockchain fue acuñado por primera vez en 2008 en el whitepaper: "Bitcoin: A Peer-to-Peer Electronic Cash System" por el conocido, y a la vez, desconocido Satoshi Nakamoto (pues la identidad de esta persona o grupo es aún desconocida.) considerado(s) padre(s) del Blockchain y el Bitcoin. En 2009 esta teoría se llevo a la práctica, naciendo así, la primera red Blockchain para transacciones monetarias digitales y descentralizadas : el Bitcoin.**¿En qué consiste esta tecnología?
**
Una Blockchain o Cadena de Bloques es un conjunto de registros que están vinculados y protegidos mediante técnicas de criptografía. Cada bloque o registro contiene un dato. La información de un bloque se traduce a una serie de dígitos llamado Previous Hash y, a su vez, la información del bloque y el Prev. Hash se transforman en otro código denominado Hash, que es como la huella dactilar del bloque.Juan Miguel Martos
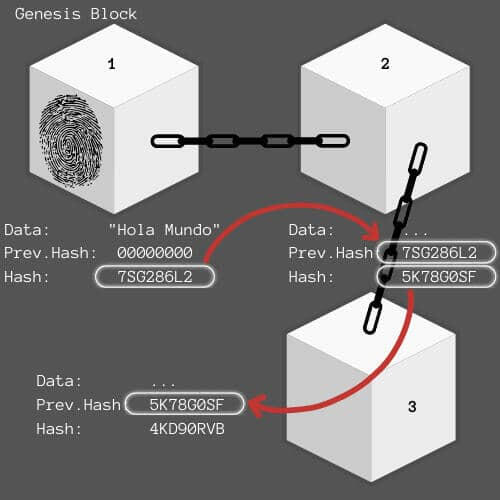
La Cadena de Bloques se origina a partir del Genesis Block o el Bloque Generador. ¿Pero cómo se encadena con otros bloques de información? Imaginemos que el bloque número 1, el genesis, ha sido creado y queremos añadir otro bloque de información; este segundo bloque llevará asociado como Prev. Hash el Hash del bloque genesis de esta manera ambos quedan encadenados. En este momento, a través de operaciones criptográficas, se genera un Hash para el bloque 2 combinando la información del propio bloque y la de su Prev. Hash. El tercer bloque se encadenaría de la misma manera: Su Prev. Hash será el Hash del bloque 2. De esta manera se crea una cadena de bloques con información distinta y vinculados criptográficamente.¿Qué sucede si se manipula la información de un bloque?Si esto ocurre, automáticamente el Hash del bloque en cuestión cambiará. De modo que el Prev. Hash registrado del siguiente no coincidirá con él. En este punto la cadena se rompe y será un indicativo de que los datos están en peligro.
Contacta conmigo
Si tienes alguna pregunta, sugerencia o idea que quieras compartir escríbeme y te atenderé con mucho gusto:

Entre el código y la bolsa:
La ciencia oculta de la innovación financiera
Mi historia en el mundo de la inversión y la tecnología comienza durante mi carrera en Física. A parte de las grandes teorías y teoremas matemáticos usados para describir el comportamiento del universo y la realidad, allí aprendí lenguajes de programación para resolver problemas complejos o incluso sin solución analítica. Esta disrupción tecnológica en mi vida hizo que me preguntase si era posible, o no, llevar la tecnología más allá de aquello para lo que fue creada, o al menos más allá de aquello que me enseñaron ¿Cómo podría mejorar mi vida con estos conocimientos?En paralelo a mi carrera empecé a formarme de manera autodidacta en el campo de la inteligencia artificial con el fin de utilizarla en la inversión y los mercados financieros.Trabajé en la creación de tecnologías Blockchain en Green Light Digital dónde tuve el placer de desenvolverme como Lead Blockchain & Data Engineer en proyectos cómo DesoNoCode y Zirkels.Más tarde me dediqué al desarrollo de modelos predictivos, ingeniería de datos y computación en la nube en Minsait Payments.Actualmente invierto mi tiempo en lo que desde un inicio ha sido mi pasión: Descifrar el mercado bursátil mediante las matemáticas y la tecnología.Juan Miguel Martos
¡Muchas gracias por tu tiempo!
Te atenderé lo antes posible.